
Adriano Vieira
terça-feira, 12 de março de 2019
Curso Fast.AI Deep Learning [Lição 1]
Lição 1 e Verificação de ambiente
Bem-vindos à lição 1! Para aqueles que estão usando um Jupyter Notebook pela primeira vez, vocês podem aprender sobre essa ferramenta útil em um tutorial que preparamos especialmente para vocês; clique em Arquivo -> Abrir agora e clique em 00_notebook_tutorial.ipynb.
Nesta lição, construiremos nosso primeiro classificador de imagens do zero e veremos se conseguimos obter resultados de alto nível. Vamos lá!
Cada notebook começa com as três linhas a seguir; elas garantem que quaisquer edições feitas nas bibliotecas sejam recarregadas aqui automaticamente e também que quaisquer gráficos ou imagens exibidos sejam exibidos neste notebook.
%reload_ext autoreload
%autoreload 2
%matplotlib inline
Importamos todos os pacotes necessários. Trabalharemos com a biblioteca fastai V1, que está sobreposta ao Pytorch 1.0. A biblioteca fastai oferece muitas funções úteis que nos permitem construir redes neurais e treinar nossos modelos de forma rápida e fácil.
from fastai.vision import *
from fastai.metrics import error_rate
Caso você estija usando um computador com uma GPU excepcionalmente pequena, poderá receber um erro de falta de memória ao executar este notebook. Se isso acontecer, clique em Kernel -> Reiniciar, descomente a segunda linha abaixo para usar um tamanho de lote menor (você aprenderá tudo sobre isso durante o curso) e tente novamente.
#bs = 64
bs = 16 # uncomment this line if you run out of memory even after clicking Kernel->Restart
Análise dos dados
Utilizaremos o Oxford-IIIT Pet Dataset de O. M. Parkhi et al., 2012, que apresenta 12 raças de gatos e 25 raças de cães. Nosso modelo precisará aprender a diferenciar entre essas 37 categorias distintas. De acordo com o artigo deles, a melhor precisão obtida em 2012 foi de 59,21%, utilizando um modelo complexo específico para detecção de animais de estimação, com modelos separados de “Imagem”, “Cabeça” e “Corpo” para as fotos dos animais. Vamos ver o quão precisos podemos ser usando aprendizado profundo!
Utilizaremos a função untar_data, para a qual devemos passar uma URL como argumento e que fará o download e a extração dos dados.
help(untar_data)
Help on function untar_data in module fastai.datasets:
untar_data(url: str, fname: Union[pathlib.Path, str] = None, dest: Union[pathlib.Path, str] = None, data=True, force_download=False) -> pathlib.Path
Download `url` to `fname` if it doesn't exist, and un-tgz to folder `dest`.
path = untar_data(URLs.PETS); path
PosixPath('$HOME/.fastai/data/oxford-iiit-pet')
path.ls()
[PosixPath('$HOME/.fastai/data/oxford-iiit-pet/images'),
PosixPath('$HOME/.fastai/data/oxford-iiit-pet/annotations')]
path_anno = path/'annotations'
path_img = path/'images'
A primeira coisa que fazemos ao abordar um problema é analisar os dados. Sempre precisamos entender muito bem qual é o problema e como os dados se parecem antes de descobrir como resolvê-lo. Analisar os dados significa entender como os diretórios de dados são estruturados, quais são os rótulos e como algumas imagens de exemplo se parecem.
A principal diferença entre o tratamento de conjuntos de dados de classificação de imagens é a forma como os rótulos são armazenados. Neste conjunto de dados específico, os rótulos são armazenados nos próprios nomes de arquivo. Precisaremos extraí-los para poder classificar as imagens nas categorias corretas. Felizmente, a biblioteca fastai possui uma função útil feita exatamente para isso, ImageDataBunch.from_name_re, que obtém os rótulos dos nomes de arquivo usando uma expressão regular.
fnames = get_image_files(path_img)
fnames[:5]
[PosixPath('$HOME/.fastai/data/oxford-iiit-pet/images/staffordshire_bull_terrier_83.jpg'),
PosixPath('$HOME/.fastai/data/oxford-iiit-pet/images/staffordshire_bull_terrier_71.jpg'),
PosixPath('$HOME/.fastai/data/oxford-iiit-pet/images/staffordshire_bull_terrier_65.jpg'),
PosixPath('$HOME/.fastai/data/oxford-iiit-pet/images/beagle_51.jpg'),
PosixPath('$HOME/.fastai/data/oxford-iiit-pet/images/english_setter_163.jpg')]
np.random.seed(2)
pat = r'/([^/]+)_\d+.jpg$'
data = ImageDataBunch.from_name_re(path_img, fnames, pat, ds_tfms=get_transforms(), size=224, bs=bs
).normalize(imagenet_stats)
data.show_batch(rows=3, figsize=(7,6))

print(data.classes)
len(data.classes),data.c
['Abyssinian', 'Bengal', 'Birman', 'Bombay', 'British_Shorthair', 'Egyptian_Mau', 'Maine_Coon', 'Persian', 'Ragdoll', 'Russian_Blue', 'Siamese', 'Sphynx', 'american_bulldog', 'american_pit_bull_terrier', 'basset_hound', 'beagle', 'boxer', 'chihuahua', 'english_cocker_spaniel', 'english_setter', 'german_shorthaired', 'great_pyrenees', 'havanese', 'japanese_chin', 'keeshond', 'leonberger', 'miniature_pinscher', 'newfoundland', 'pomeranian', 'pug', 'saint_bernard', 'samoyed', 'scottish_terrier', 'shiba_inu', 'staffordshire_bull_terrier', 'wheaten_terrier', 'yorkshire_terrier']
(37, 37)
Treinamento: resnet34
Agora, começaremos a treinar nosso modelo. Usaremos uma estrutura de rede neural convolucional e uma cabeça totalmente conectada com uma única camada oculta como classificador. Não sabe o que isso significa? Não se preocupe, nos aprofundaremos nas próximas lições. Por enquanto, você precisa saber que estamos construindo um modelo que receberá imagens como entrada e produzirá a probabilidade prevista para cada uma das categorias (neste caso, terá 37 saídas).
Treinaremos para 4 épocas (4 ciclos em todos os nossos dados).
learn = cnn_learner(data, models.resnet34, metrics=error_rate)
learn.model
Sequential(
(0): Sequential(
(0): Conv2d(3, 64, kernel_size=(7, 7), stride=(2, 2), padding=(3, 3), bias=False)
(1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace)
(3): MaxPool2d(kernel_size=3, stride=2, padding=1, dilation=1, ceil_mode=False)
(4): Sequential(
(0): BasicBlock(
(conv1): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(1): BasicBlock(
(conv1): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(2): BasicBlock(
(conv1): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(5): Sequential(
(0): BasicBlock(
(conv1): Conv2d(64, 128, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(downsample): Sequential(
(0): Conv2d(64, 128, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): BasicBlock(
(conv1): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(2): BasicBlock(
(conv1): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(3): BasicBlock(
(conv1): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(6): Sequential(
(0): BasicBlock(
(conv1): Conv2d(128, 256, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(downsample): Sequential(
(0): Conv2d(128, 256, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): BasicBlock(
(conv1): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(2): BasicBlock(
(conv1): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(3): BasicBlock(
(conv1): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(4): BasicBlock(
(conv1): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(5): BasicBlock(
(conv1): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(7): Sequential(
(0): BasicBlock(
(conv1): Conv2d(256, 512, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace)
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(downsample): Sequential(
(0): Conv2d(256, 512, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): BasicBlock(
(conv1): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace)
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(2): BasicBlock(
(conv1): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace)
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
)
(1): Sequential(
(0): AdaptiveConcatPool2d(
(ap): AdaptiveAvgPool2d(output_size=1)
(mp): AdaptiveMaxPool2d(output_size=1)
)
(1): Flatten()
(2): BatchNorm1d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(3): Dropout(p=0.25)
(4): Linear(in_features=1024, out_features=512, bias=True)
(5): ReLU(inplace)
(6): BatchNorm1d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(7): Dropout(p=0.5)
(8): Linear(in_features=512, out_features=37, bias=True)
)
)
learn.fit_one_cycle(4)
Total time: 02:55
| epoch | train_loss | valid_loss | error_rate | time |
|---|---|---|---|---|
| 0 | 0.753717 | 0.352798 | 0.119080 | 00:44 |
| 1 | 0.598169 | 0.315887 | 0.106901 | 00:43 |
| 2 | 0.394332 | 0.250617 | 0.073072 | 00:43 |
| 3 | 0.291477 | 0.236644 | 0.072395 | 00:43 |
learn.save('stage-1')
Resultados
Vamos ver os resultados que obtivemos.
Primeiramente, veremos quais foram as categorias que o modelo mais confundiu entre si. Tentaremos verificar se o que o modelo previu foi razoável ou não. Nesse caso, os erros parecem razoáveis (nenhum dos erros parece obviamente ingênuo). Isso é um indicador de que nosso classificador está funcionando corretamente.
Além disso, quando plotamos a matriz de confusão, podemos ver que a distribuição é bastante assimétrica: o modelo comete os mesmos erros repetidamente, mas raramente confunde outras categorias. Isso sugere que ele simplesmente tem dificuldade em distinguir algumas categorias específicas entre si; esse é um comportamento normal.
interp = ClassificationInterpretation.from_learner(learn)
losses,idxs = interp.top_losses()
len(data.valid_ds)==len(losses)==len(idxs)
True
interp.plot_top_losses(9, figsize=(15,11))

doc(interp.plot_top_losses)
interp.plot_confusion_matrix(figsize=(12,12), dpi=60)

interp.most_confused(min_val=2)
[('american_pit_bull_terrier', 'staffordshire_bull_terrier', 10),
('staffordshire_bull_terrier', 'american_pit_bull_terrier', 8),
('Ragdoll', 'Birman', 6),
('Abyssinian', 'Bengal', 4),
('Egyptian_Mau', 'Bengal', 4),
('British_Shorthair', 'Russian_Blue', 3),
('Russian_Blue', 'British_Shorthair', 3),
('Siamese', 'Birman', 3),
('american_bulldog', 'american_pit_bull_terrier', 3),
('boxer', 'american_bulldog', 3),
('english_setter', 'english_cocker_spaniel', 3),
('Bengal', 'Egyptian_Mau', 2),
('Birman', 'Ragdoll', 2),
('Birman', 'Siamese', 2),
('Maine_Coon', 'Ragdoll', 2),
('american_pit_bull_terrier', 'american_bulldog', 2),
('basset_hound', 'beagle', 2),
('chihuahua', 'miniature_pinscher', 2),
('staffordshire_bull_terrier', 'american_bulldog', 2),
('yorkshire_terrier', 'havanese', 2)]
Ajuste fino e taxas de aprendizado
Como nosso modelo está funcionando conforme o esperado, vamos descongelá-lo e treiná-lo um pouco mais.
learn.unfreeze()
learn.fit_one_cycle(1)
Total time: 01:04
| epoch | train_loss | valid_loss | error_rate | time |
|---|---|---|---|---|
| 0 | 0.748233 | 0.381591 | 0.119080 | 01:04 |
learn.load('stage-1');
learn.lr_find()
LR Finder is complete, type {learner_name}.recorder.plot() to see the graph.
learn.recorder.plot()
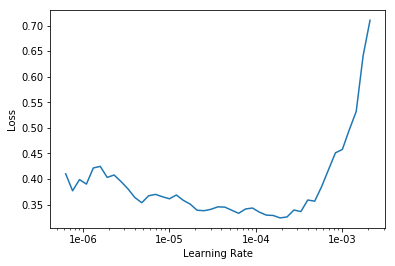
learn.unfreeze()
learn.fit_one_cycle(2, max_lr=slice(1e-6,1e-4))
Total time: 02:09
| epoch | train_loss | valid_loss | error_rate | time |
|---|---|---|---|---|
| 0 | 0.290971 | 0.227893 | 0.073748 | 01:04 |
| 1 | 0.299255 | 0.224813 | 0.069012 | 01:04 |
That’s a pretty accurate model!
Treinamento: resnet50
Agora, treinaremos da mesma forma que antes, mas com uma ressalva: em vez de usar o resnet34 como backbone, usaremos o resnet50 (o resnet34 é uma rede residual de 34 camadas, enquanto o resnet50 possui 50 camadas. Isso será explicado posteriormente no curso e você poderá aprender os detalhes no artigo sobre resnet).
Basicamente, o resnet50 geralmente tem um desempenho melhor porque é uma rede mais profunda e com mais parâmetros. Vamos ver se conseguimos um desempenho melhor aqui. Para ajudar, vamos usar imagens maiores também, pois assim a rede pode ver mais detalhes. Reduzimos um pouco o tamanho do lote, pois, caso contrário, essa rede maior exigirá mais memória da GPU.
data = ImageDataBunch.from_name_re(path_img, fnames, pat, ds_tfms=get_transforms(),
size=299, bs=bs//2).normalize(imagenet_stats)
learn = cnn_learner(data, models.resnet50, metrics=error_rate)
learn.lr_find()
learn.recorder.plot()
LR Finder is complete, type {learner_name}.recorder.plot() to see the graph.
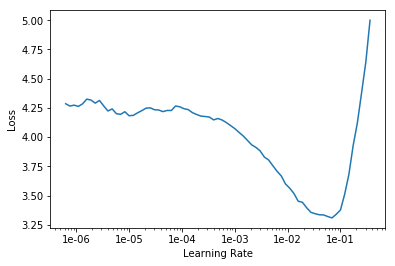
learn.fit_one_cycle(8)
Total time: 21:49
| epoch | train_loss | valid_loss | error_rate | time |
|---|---|---|---|---|
| 0 | 0.772291 | 0.325861 | 0.110961 | 02:43 |
| 1 | 0.693798 | 0.264864 | 0.089986 | 02:43 |
| 2 | 0.562693 | 0.225644 | 0.074425 | 02:43 |
| 3 | 0.489018 | 0.194478 | 0.066306 | 02:43 |
| 4 | 0.358710 | 0.249303 | 0.072395 | 02:44 |
| 5 | 0.318184 | 0.184728 | 0.057510 | 02:43 |
| 6 | 0.320732 | 0.161122 | 0.053451 | 02:42 |
| 7 | 0.293470 | 0.155643 | 0.051421 | 02:45 |
learn.save('stage-1-50')
É impressionante como é possível reconhecer raças de animais de estimação com tanta precisão! Vamos ver se um ajuste fino completo ajuda:
learn.unfreeze()
learn.fit_one_cycle(3, max_lr=slice(1e-6,1e-4))
Total time: 11:29
| epoch | train_loss | valid_loss | error_rate | time |
|---|---|---|---|---|
| 0 | 0.251561 | 0.172114 | 0.049391 | 03:49 |
| 1 | 0.292834 | 0.208985 | 0.050744 | 03:48 |
| 2 | 0.216993 | 0.164900 | 0.048714 | 03:51 |
Caso contrário, você sempre pode voltar ao modelo anterior.
learn.load('stage-1-50');
interp = ClassificationInterpretation.from_learner(learn)
interp.most_confused(min_val=2)
[('american_pit_bull_terrier', 'american_bulldog', 5),
('american_pit_bull_terrier', 'staffordshire_bull_terrier', 5),
('staffordshire_bull_terrier', 'american_bulldog', 5),
('Bengal', 'Egyptian_Mau', 4),
('Ragdoll', 'Birman', 4),
('Siamese', 'Birman', 3),
('beagle', 'basset_hound', 3),
('staffordshire_bull_terrier', 'american_pit_bull_terrier', 3),
('British_Shorthair', 'Russian_Blue', 2),
('Ragdoll', 'Persian', 2),
('american_bulldog', 'american_pit_bull_terrier', 2),
('american_bulldog', 'boxer', 2),
('basset_hound', 'beagle', 2),
('boxer', 'american_bulldog', 2),
('chihuahua', 'shiba_inu', 2),
('english_cocker_spaniel', 'newfoundland', 2)]
Outros formatos de dados
path = untar_data(URLs.MNIST_SAMPLE); path
PosixPath('$HOME/.fastai/data/mnist_sample')
tfms = get_transforms(do_flip=False)
data = ImageDataBunch.from_folder(path, ds_tfms=tfms, size=26)
data.show_batch(rows=3, figsize=(5,5))

learn = cnn_learner(data, models.resnet18, metrics=accuracy)
learn.fit(2)
Downloading: "https://download.pytorch.org/models/resnet18-5c106cde.pth" to $HOME/.torch/models/resnet18-5c106cde.pth
46827520it [00:03, 14842024.16it/s]
Total time: 00:10
| epoch | train_loss | valid_loss | accuracy | time |
|---|---|---|---|---|
| 0 | 0.176300 | 0.087094 | 0.968106 | 00:05 |
| 1 | 0.107516 | 0.040531 | 0.984789 | 00:04 |
df = pd.read_csv(path/'labels.csv')
df.head()
| name | label | |
|---|---|---|
| 0 | train/3/7463.png | 0 |
| 1 | train/3/21102.png | 0 |
| 2 | train/3/31559.png | 0 |
| 3 | train/3/46882.png | 0 |
| 4 | train/3/26209.png | 0 |
data = ImageDataBunch.from_csv(path, ds_tfms=tfms, size=28)
data.show_batch(rows=3, figsize=(5,5))
data.classes
[0, 1]

data = ImageDataBunch.from_df(path, df, ds_tfms=tfms, size=24)
data.classes
[0, 1]
fn_paths = [path/name for name in df['name']]; fn_paths[:2]
[PosixPath('$HOME/.fastai/data/mnist_sample/train/3/7463.png'),
PosixPath('$HOME/.fastai/data/mnist_sample/train/3/21102.png')]
pat = r"/(\d)/\d+\.png$"
data = ImageDataBunch.from_name_re(path, fn_paths, pat=pat, ds_tfms=tfms, size=24)
data.classes
['3', '7']
data = ImageDataBunch.from_name_func(path, fn_paths, ds_tfms=tfms, size=24,
label_func = lambda x: '3' if '/3/' in str(x) else '7')
data.classes
['3', '7']
labels = [('3' if '/3/' in str(x) else '7') for x in fn_paths]
labels[:5]
['3', '3', '3', '3', '3']
data = ImageDataBunch.from_lists(path, fn_paths, labels=labels, ds_tfms=tfms, size=24)
data.classes
['3', '7']